
Coffee Rating Predictor
As part of my graduate Data Mining course, I worked with my team, The Roasters, to build a machine learning model that predicts whether a coffee review reflects an "Outstanding" or "Average" coffee experience. We aimed to provide insights for coffee roasters and consumers by analyzing hundreds of real-world coffee reviews and identifying patterns in flavor, aroma, and overall sentiment.


Coffee Rating Predictor Details
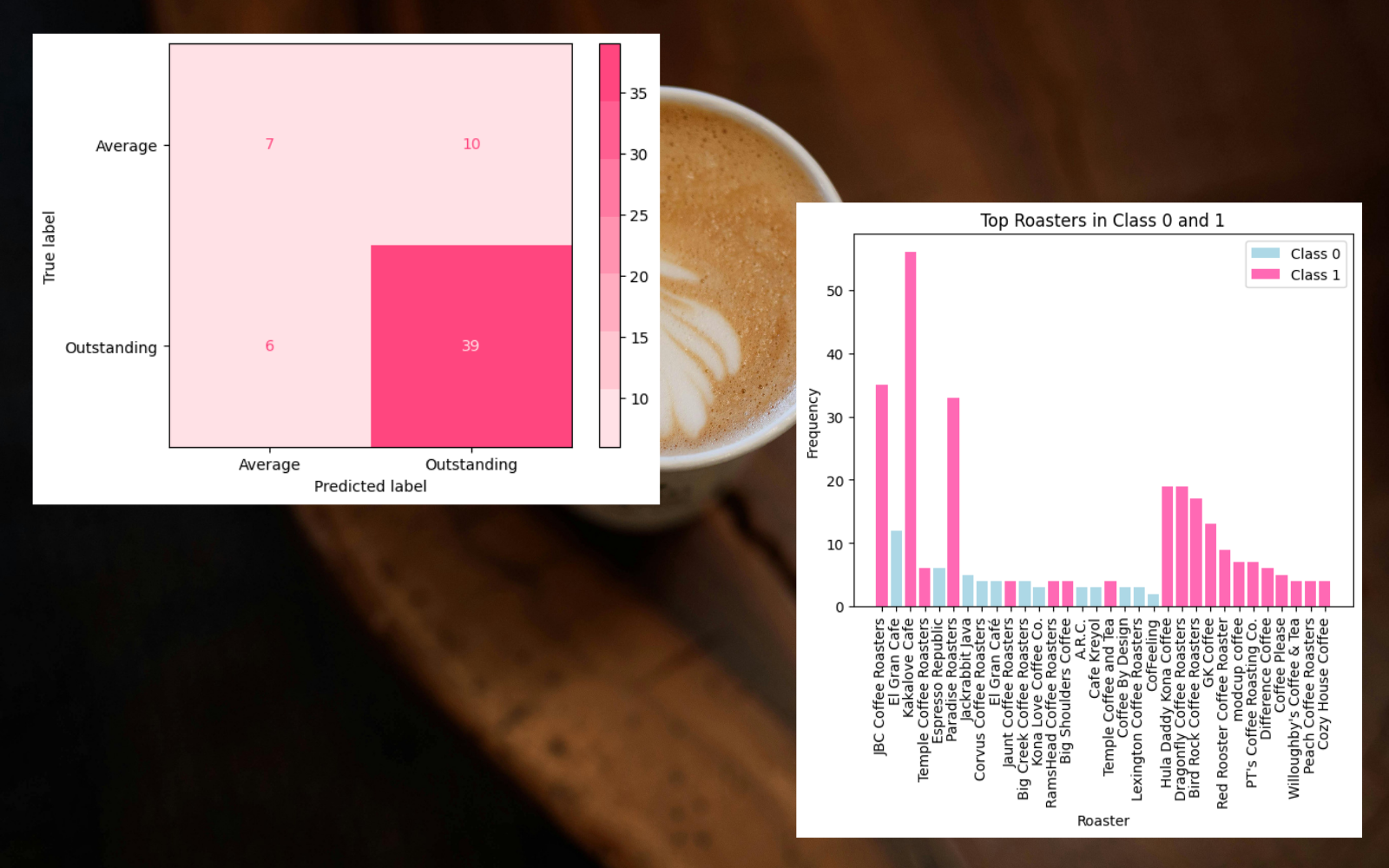
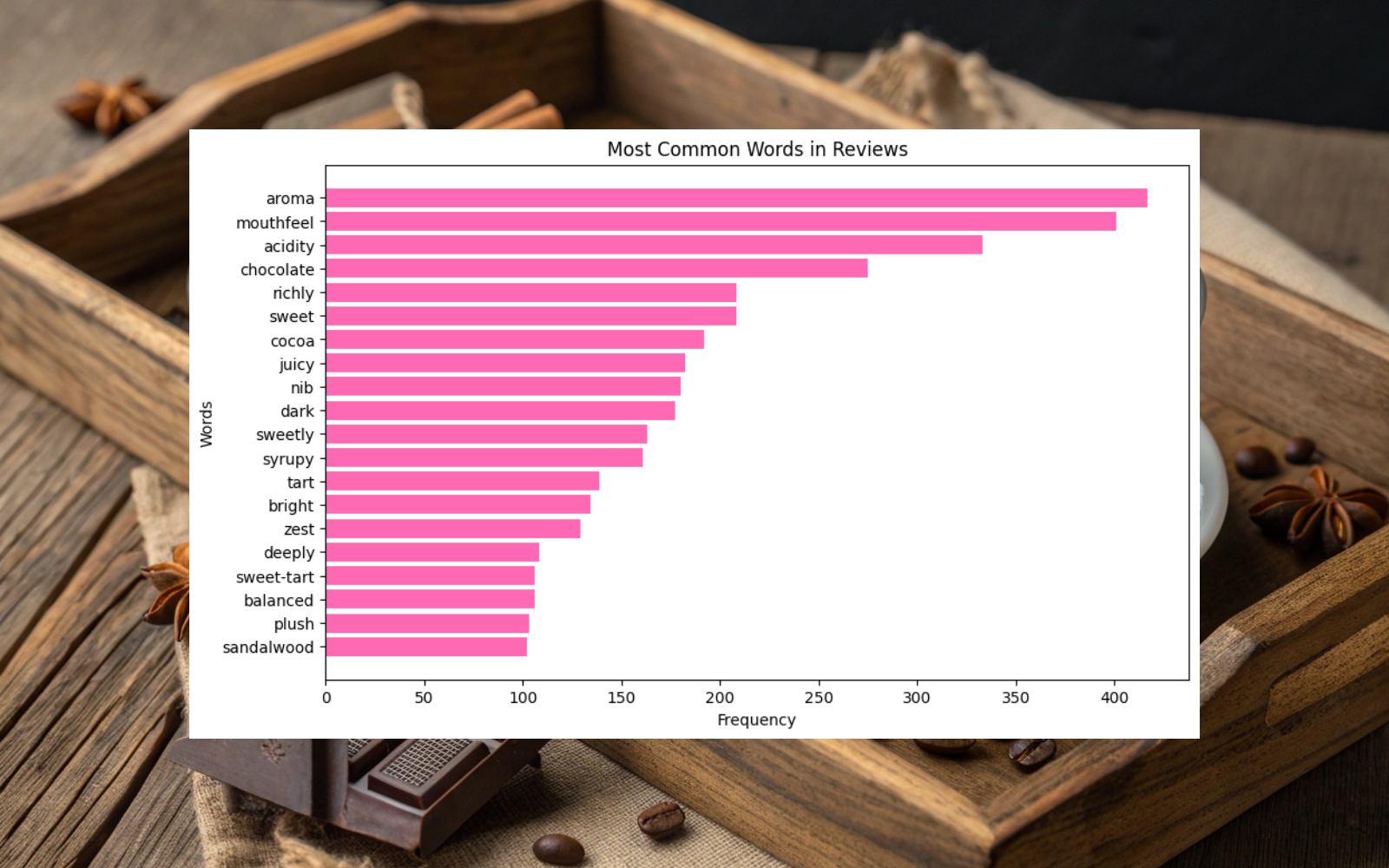
We began by preprocessing 300 coffee reviews to ensure data quality. Null values, punctuation, and custom stopwords such as "cup" and "notes" were removed, and categorical variables such as roaster, roast, and origin were converted into dummy variables. For feature engineering, we created a sentiment column using NLTK's SentimentIntensityAnalyzer combined with positive and negative word lists derived from the dataset. This allowed our model to capture nuanced language patterns in coffee reviews. We visualized the data using bar charts and word clouds for the top 20 most common positive and negative words, highlighting trends in consumer preferences.
The model itself is a Gaussian Naive Bayes classifier trained on the preprocessed dataset, achieving 83% accuracy when predicting positive, "Outstanding", reviews. We validated the model using F1 scores and confusion matrices to ensure balanced performance across classes. Finally, the model was applied to a separate test dataset, and predictions were exported as a CSV for downstream analysis.
As a Coffee Roaster, the outcome of specific descriptive words can inform marketing strategies...[and] a product development opportunity could be the introduction of star, jasmine-like flavors in future coffee options.
The Roasters Team
Data Mining Final Project Report
The model effectively identifies patterns in coffee reviews that differentiate highly-rated products from average ones, providing important insights for both roasters and consumers. By analyzing language trends, the project highlights which descriptors and flavors are most associated with positive reviews.
Project information
- CategoryData Science
- TechnologiesPython, Jupyter Notebook, Pandas, Scikit-learn, NLTK, Matplotlib, WordCloud
- SkillsETL (Extract, Transform, Load), Feature engineering, Text mining and natural language processing (NLP), Sentiment analysis, Exploratory data analysis (EDA), Data visualization, Machine learning model building and evaluation, Cross-validation and performance metrics
- Project date April 2024 - May 2024
- Final Report Final Report Download
- Project URL GitHub Link